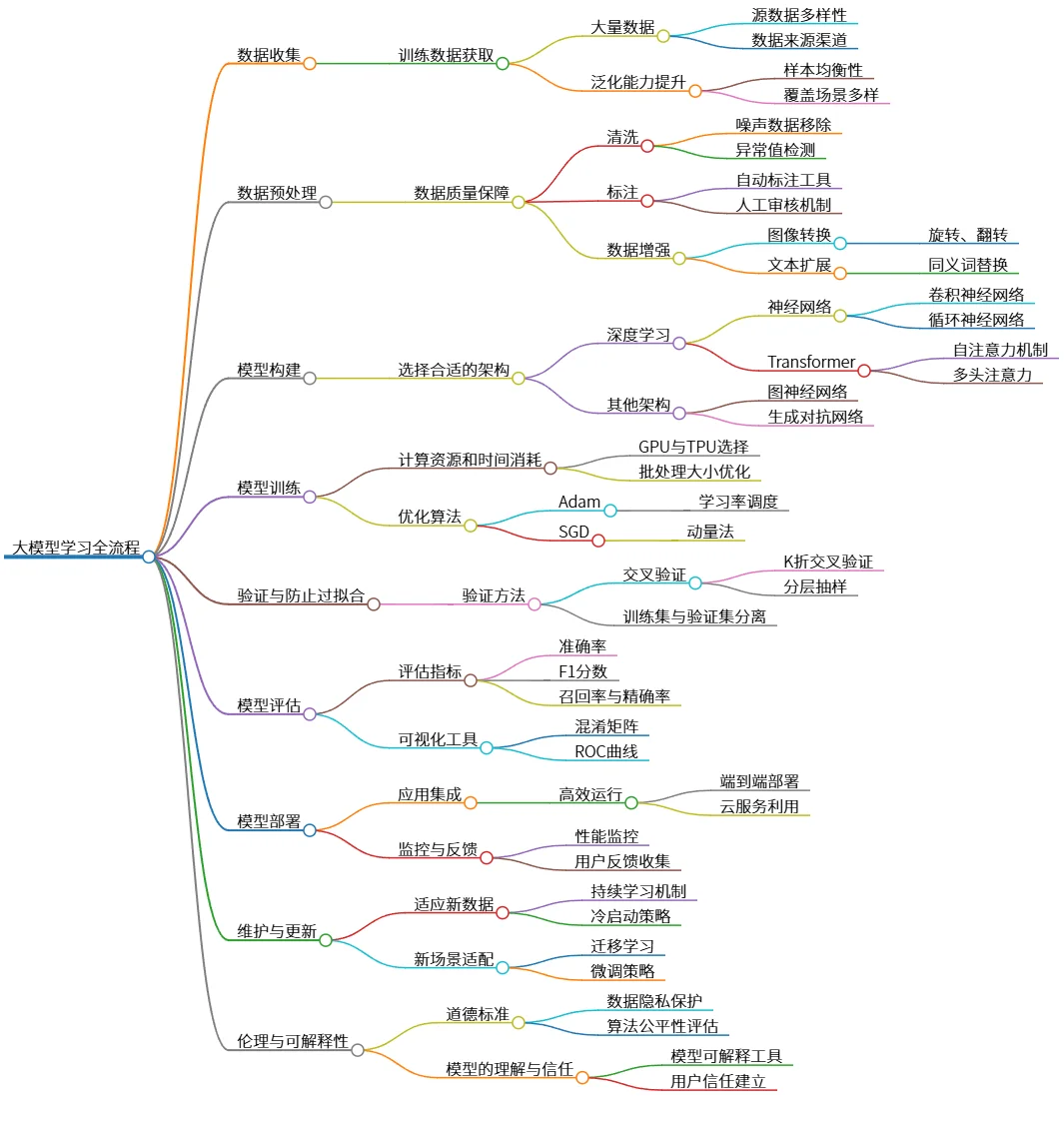
大模型学习全流程:数据收集、处理、构建与评估
该思维导图概述了大模型学习的多个关键环节,包括数据收集、预处理、模型构建、训练、验证、评估、部署、维护和伦理。强调了获取大量高质量数据的重要性,选择合适的网络架构,并利用优化算法进行有效训练。提出使用交叉验证来防止过拟合,定义评估指标以衡量模型表现。同时关注模型在实际应用中的集成、适应性以及伦理问题,确保模型的可解释性和用户信任。
源码
# 大模型学习全流程
## 数据收集
- 训练数据获取
- 大量数据
- 源数据多样性
- 数据来源渠道
- 泛化能力提升
- 样本均衡性
- 覆盖场景多样
## 数据预处理
- 数据质量保障
- 清洗
- 噪声数据移除
- 异常值检测
- 标注
- 自动标注工具
- 人工审核机制
- 数据增强
- 图像转换
- 旋转、翻转
- 文本扩展
- 同义词替换
## 模型构建
- 选择合适的架构
- 深度学习
- 神经网络
- 卷积神经网络
- 循环神经网络
- Transformer
- 自注意力机制
- 多头注意力
- 其他架构
- 图神经网络
- 生成对抗网络
## 模型训练
- 计算资源和时间消耗
- GPU与TPU选择
- 批处理大小优化
- 优化算法
- Adam
- 学习率调度
- SGD
- 动量法
## 验证与防止过拟合
- 验证方法
- 交叉验证
- K折交叉验证
- 分层抽样
- 训练集与验证集分离
## 模型评估
- 评估指标
- 准确率
- F1分数
- 召回率与精确率
- 可视化工具
- 混淆矩阵
- ROC曲线
## 模型部署
- 应用集成
- 高效运行
- 端到端部署
- 云服务利用
- 监控与反馈
- 性能监控
- 用户反馈收集
## 维护与更新
- 适应新数据
- 持续学习机制
- 冷启动策略
- 新场景适配
- 迁移学习
- 微调策略
## 伦理与可解释性
- 道德标准
- 数据隐私保护
- 算法公平性评估
- 模型的理解与信任
- 模型可解释工具
- 用户信任建立
图片